用异步协程写一个爬虫 (2)
本文译自: A Web Crawler With asyncio Coroutines。
在上一篇的最后, 我们提到了多线程与异步的一些问题, 下面来介绍一下 Python 的协程(coroutines), 它兼具了多线程与异步的一些优点.
Coroutines
其实是存在 “美貌与智慧” 兼得的方法的。 将回调的有效性与多线程程序的经典好处结合到一起的异步代码是很有可能的。其方法就是使用叫做 “协程(coroutines)” 的模式。使用 Python3.4 中的标准 asyncio 库,和一个叫做 “aiohttp” 的 package, 在一个协程中获取一个 URL 非常直观:
@asyncio.coroutines
def fetch(self, url):
response = yield from self.session.get(url)
body = yield from response.read()
它同时还具有伸缩性 (scalable)。 与每个线程 50k 的内存消耗与操作系统对于线程的严格限制相比,一个 Python 的协程仅仅消耗 3k . Python 可以轻松地启动成百上千的协程。
协程的概念其实很简单: 它是一个能够被暂停和重新启动的子程序。尽管线程被操作系统抢占式的多任务安排,协程的多任务是协作式的:它们选择合适暂停,然后下一次运行哪一个协程。
协程有许多实现,即使是在 Python 中也有好几个实现。在 Python3.4 的标准 “asyncio” 库中, 协程基于生成器,使用了 “yield from” 声明. 自从 Python 3.5 , 线程已经成为语言的一个天然特性。不过,理解在 Python 3.4 中首先实现的协程,使用预先存在的语言功能,是利用 Python 3.5 天然协程的基础。
为了解释 Python 3.4 中基于生成器的协程,我们将会阐述生成器是什么以及在 asyncio 它们是如何用作协程。相信你跟我们乐于书写这部分一样乐于阅读. 一旦解释完基于生成器的协程,我们将会在我们的异步网络爬虫中使用它们。
How Python Generators Work
在理解 Python 的生成器之前,你必须要理解普通的 Python 函数是如何工作的。 通常来说,当一个Python 函数调用一个 subroutine 时,这个 subroutine 会保留控制直到返回或是抛出一个异常。然后控制返回给调用者:
>>> def foo():
... bar()
...
>>> def bar():
... pass
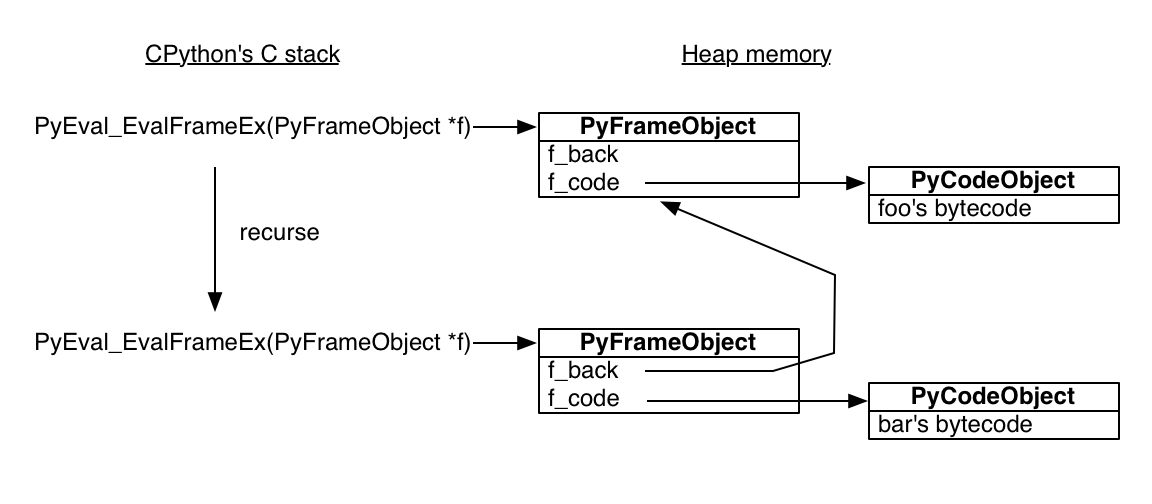
标准的 Python 解释器使用 C 写的。执行一个 Python 函数的 C 函数叫做 PyEval_EvalFrameEx. 它需要一个 Python stack frame 对象,在 frame 的上下文中对 Python 字节码进行求值。 这里是 foo 的字节码:
>>> import dis
>>> dis.dis(foo)
2 0 LOAD_GLOBAL 0 (bar)
3 CALL_FUNCTION 0 (0 positional, 0 keyword pair)
6 POP_TOP
7 LOAD_CONST 0 (None)
10 RETURN_VALUE
foo 函数将 bar 加载到栈上然后进行调用,并将其从栈上弹出返回值,将 None 入栈,返回 None.
当 PyEval_EvalFrameEx 遇到 CALL_FUNCTION 字节码,它会调用一个新的 Python stack frame 然后递归: 也就是说,它在新的 frame 下递归地调用 PyEval_EvalFrameEx , 以此来执行 bar.
非常重要的一点是要知道 Python stack frame 是分配于堆内存上! Python 解释器是一个普通的 C 程序而已,所以它的的 stack frame 也是正常的 stack frame. 但是它控制的 Python stack frame 在堆上。除了其他惊喜,这还意味着一个 Python stack frame 能够比它的函数调用存活时间更长。 为了交互式地观察这一点,在 bar 内部保存当前的 frame:
>>> import inspect
>>> frame = None
>>> def foo():
... bar()
...
>>> def bar():
... global frame
... frame = inspect.currentframe()
...
>>> foo()
>>> # The frame was executing the code for 'bar'.
>>> frame.f_code.co_name
'bar'
>>> # Its back pointer refers to the frame for 'foo'.
>>> caller_frame = frame.f_back
>>> caller_frame.f_code.co_name
'foo'
现在开始设置 Python 生成器的阶段,它使用了同样的 building block - code objects and stack frames - 效果非凡。
这是一个生成器函数:
>>> def gen_fn():
... result = yield 1
... print('result of yield: {}'.format(result))
... result2 = yield 2
... print('result of 2nd yield: {}'.format(result2))
... return 'done'
...
当Python把 gen_fn 编译为字节码,它会看到 yield 并且知道 gen_fn 是一个生成器函数,而不是普通函数。那么他就会设置一个标记:
>>> # The generator flag is bit position 5.
>>> generator_bit = 1 << 5
>>> bool(gen_fn.__code__.co_flags & generator_bit)
True
当你调用一个生成器函数时, Python 看到生成器标志,它并不会真正的运行这个函数,而是创建一个生成器:
>>> gen = gen_fn()
>>> type(gen)
<class 'generator'>
一个 Python 生成器封装了一个 stack frame 和对某些代码的引用, gen_fn 的主体:
>>> gen.gi_code.co_name
'gen_fn'
对 gen_fn 的调用的所有生成器都指向同样的代码。但是每一个都拥有自己的 stack frame. 这个 stack frame 并不是任何真正的栈,它位于堆内存并且等待被使用:
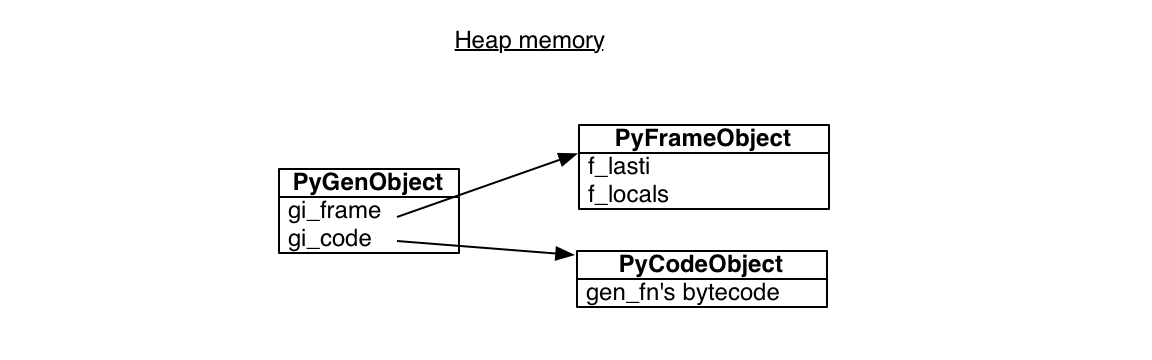
frame 有一个 “最近指令 (last instruction)” 指针,它最近执行最多的指令。开始的时候,最近指令指针为 -1, 表示生成器还没有开始:
>>> gen.gi_frame.f_lasti
-1
当我们调用 send , 生成器到底它的第一个 yield, 然后暂停。send 的返回值为 1, 因此这就是 gen 传递给 yield 表达式的值:
>>> gen.send(None)
1
生成器的指令指针现在距离开始 3 个字节码, 编译后的Python 56 个字节:
>>> gen.gi_frame.f_lasti
3
>>> len(gen.gi_code.co_code)
56
生成器可以在任何时间,从任何函数中重新开始,因为它的 stack frame 实际上并没有在栈上: 它在堆上。它在调用继承上的位置并不是固定的,它也不需要像普通函数那样遵循先进后出的执行顺序。 它是自由的,没有任何限制。
我们可以发送 “hello” 给生成器,那么 “hello” 会成为 yield 表达式的结果, 生成器会一直持续直到它产生 2:
>>> gen.send('hello')
result of yield: hello
2
它的 stack frame 现在包含了本地变量 result:
>>> gen.gi_frame.f_locals
{'result': 'hello'}
由 gen_fn 创建的其他生成器将会拥有它们自己独立的 stack frame 和 本地变量。
当我们再次调用 send 时,生成器将会从第二个 yield 继续,并且最终抛出一个特殊的 StopIteration 异常:
>>> gen.send('goodbye')
result of 2nd yield: goodbye
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration: done
这个异常有一个值,这个值就是生成器的返回值: 字符串 "done" .
Building Coroutines With Generators
所以一个生成器可以暂停, 通过一个值来重新启动,并且有一个返回值。听起来像是可以基于此来构建一个异步程序模型的一个不错的原型,而不必烦人的回调! 我们想要构建一个 “协程”: 一个能够与程序中其他协程合作调度的协程。我们的协程将是一个 Python 标准库 “asyncio” 的相应内容的简化版本。在 asyncio 中,我们将会使用生成器,futures, 和 “yield from” 语句。
首先我们需要有一个方式来表示一个协程等待的未知的结果。 简化版本:
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
一个 future 初始为 “pending”. 通过一个队 set_result 1 的调用来 “解决” 。
让我们调整 fetcher 来使用 future 和 协程。 写一个带有回调的 fetch:
class Fetcher:
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.connected)
def connected(self, key, mask):
print('connected!')
# And so on....
fetch 以连接一个 socket 开始,然后注册回调, connected, 当 socket 准备好以后执行。 现在我们尅将这两步组合到一个协程中:
def fetch(self):
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('xkcd.com', 80))
except BlockingIOError:
pass
f = Future()
def on_connected():
f.set_result(None)
selector.register(sock.fileno(),
EVENT_WRITE,
on_connected)
yield f
selector.unregister(sock.fileno())
print('connected!')
现在的 fetch 是一个生成器函数,而非一个普通函数,因为它包含了一个 yield 语句。 我们创建一个挂起的 future, 然后生成它来暂停 fetch 直到 socket 准备好。 内部函数 on_connected 解析 future.
当时当 future 解析的时候,什么来重新启动生成器?我们需要一个协程 “驱动器 (driver)”. 就叫它 “task” 吧.
class Task:
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
# Begin fetching http://xkcd.com/353/
fetcher = Fetcher('/353/')
Task(fetcher.fetch())
loop()
通过发送 None 给 task 来启动 fetch 生成器。 然后 fetch 运行直至它生成一个 future, 同时会被 task 捕获为 next_future .
Coordinating Coroutines
一旦 socket 连接上,我们就发送 HTTP GET 请求并读取服务器的响应。 这些步骤不再需要分散于回调之间; 我们可以将它们组合到同一个生成器函数中:
def fetch(self):
# ... connection logic from above, then:
sock.send(request.encode('ascii'))
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(),
EVENT_READ,
on_readable)
chunk = yield f
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
# Done reading.
break
这段代码,读了 socket 的全部消息,似乎通常都很有用。 我们如何才能将它从 fetch 分离并填充到一个协程中? 现在 Python 3 的 yield from 能够完成这个任务。它允许一个生成器委托另一个生成器.
为了理解为何如此,让我们回到一个简单的生成器示例:
>>> def gen_fn():
... result = yield 1
... print('result of yield: {}'.format(result))
... result2 = yield 2
... print('result of 2nd yield: {}'.format(result2))
... return 'done'
...
从另一个的生成器中调用这个生成器,使用 yield from 委托给它:
>>> # Generator function:
>>> def caller_fn():
... gen = gen_fn()
... rv = yield from gen
... print('return value of yield-from: {}'
... .format(rv))
...
>>> # Make a generator from the
>>> # generator function.
>>> caller = caller_fn()
caller 生成器表现地就如同 gen,它所委托的生成器:
>>> caller.send(None)
1
>>> caller.gi_frame.f_lasti
15
>>> caller.send('hello')
result of yield: hello
2
>>> caller.gi_frame.f_lasti # Hasn't advanced.
15
>>> caller.send('goodbye')
result of 2nd yield: goodbye
return value of yield-from: done
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
当 caller 生成自 gen, caller 并不优先。 注意到它的指令指针停留在 15,yield from 语句的地方,即使是当内部的生成器 gen 先于一个 yield 语句进行到下一个 2。 从我们的视角来看 caller, 我们无法区分它所产生的值是来自 caller 还是它所代表的生成器。 从内部的 gen, 我们无法区分值是发送自 caller 还是 caller 外部。 yield from 语句是一个无摩擦的通道,尽管这些值会流入流出 gen 直到 gen 完成。
一个协程可以通过 yield from 将工作委托给一个子协程并接受任务结果。 注意,上面的 caller 打印出 “return value of yield-from: done” . 当 gen 完成后, 它的返回值变成了 caller 里面的 yield from 语句的返回值:
rv = yield from gen
早先,我们批评了基于回调的异步程序的不足之处,最大的一个缺点是 “stack ripping”: 当一个回调抛出异常时,追踪栈通常并没有什么用。 它只是显示出事件循环正在运行回调,却没有指示 为什么 。 那么协程如何呢?
>>> def gen_fn():
... raise Exception('my error')
>>> caller = caller_fn()
>>> caller.send(None)
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "<input>", line 3, in caller_fn
File "<input>", line 2, in gen_fn
Exception: my error
这些信息相当有用!追踪栈显示 caller_fn 委托了 gen_fn 当它抛出错误的时候。 更有效的是,我们可以将子协程的调用包装在一个异常的 handler 猴子那个,同样适用于正常的子协程:
>>> def gen_fn():
... yield 1
... raise Exception('uh oh')
...
>>> def caller_fn():
... try:
... yield from gen_fn()
... except Exception as exc:
... print('caught {}'.format(exc))
...
>>> caller = caller_fn()
>>> caller.send(None)
1
>>> caller.send('hello')
caught uh oh
所以我们使用子协程来分离逻辑就像使用普通的子协程一样。 让我们从 fetcher 中分离一些有用的子协程。 我们写一个 read 协程来接收一个数据块:
def read(sock):
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield f # Read one chunk.
selector.unregister(sock.fileno())
return chunk
基于 read 我们使用了 read_all 协程来获取一个完整的消息:
def read_all(sock):
response = []
# Read whole response.
chunk = yield from read(sock)
while chunk:
response.append(chunk)
chunk = yield from read(sock)
return b''.join(response)
如果你仔细看的话,yield from 语句不见了,它们看起来就像是执行阻塞时 I/O 的传统程序。 但是实际上,read 和 read_all 都是协程。 read 所产生的内容会暂停 read_all 直到 I/O 完成. 当 read_all 暂停后,asyncio 的事件循环会做其他事情和等到其他的 I/O 事件; 一旦它的事件准备好了,read_all 就会以下一个循环 tick 的 read 的结果重新开始。
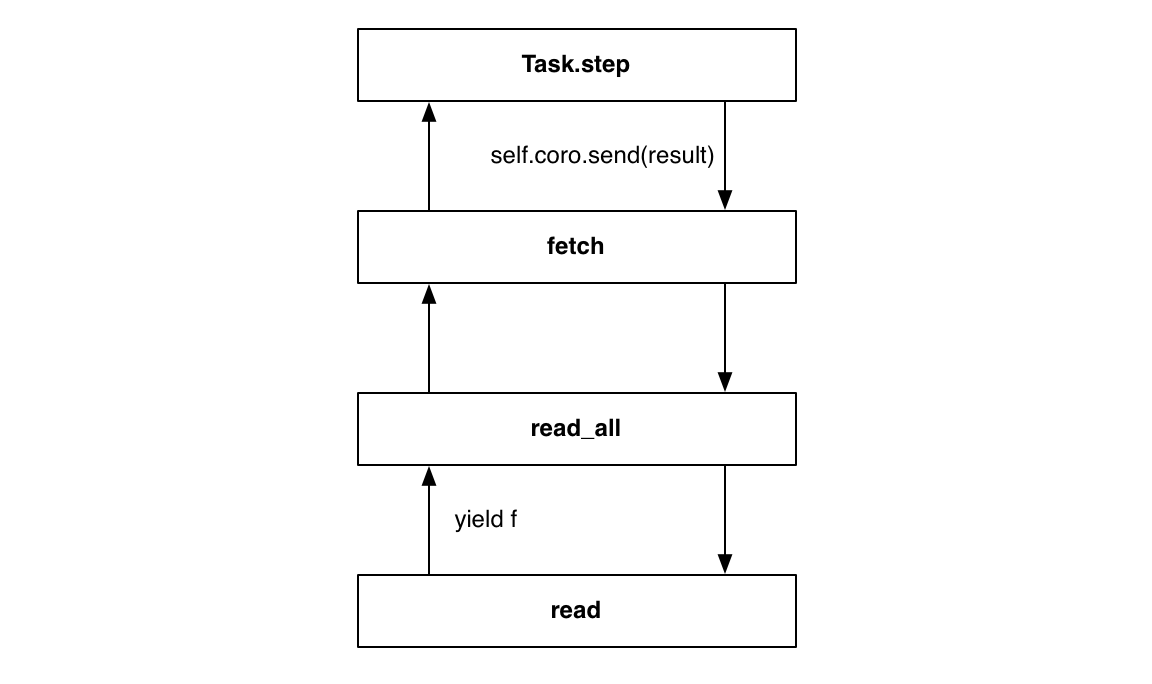
在栈底, fetch 调用 read_all:
class Fetcher:
def fetch(self):
# ... connection logic from above, then:
sock.send(request.encode('ascii'))
self.response = yield from read_all(sock)
出乎意料地,Task 类并不需要有所改变。它会像之前一样驱动外部的 fetch 协程:
Task(fetcher.fetch())
loop()
当 read 生成一个 future, task 通过 yield from 语句的通道接收 future, 更准确地说,就想好事 future 直接产生自 fetch. 当循环解析一个 future, task 将它的结果发送给 fetch, 并且值被 read 所接收, 跟 task 直接驱动 read 一样:
为了完善我们的协程实现, 我们去除一个缺点: 当等待一个 future 时使用 yield, 但是当它委托给一个子协程时使用 yield from. 如果无论当一个协程何时暂停,我们都使用 yield from 就更好了。那么一个协程就不再需要考虑它所等待的是一个什么类型的东西.
我们利用了 Python 中生成器与迭代器之间的深层次联系。 对 caller 来说,生成器很高级, 迭代器同样很高级。所以我们通过实现一个特殊的方法来使得 Future 类可迭代:
# Method on Future class.
def __iter__(self):
# Tell Task to resume me here.
yield self
return self.result
future 的 __iter__ 方法是一个产生 future 自身的协程。 现在我们来替换像这样的代码:
# f is a Future.
yield f
用这样的来替换:
# f is a Future.
yield from f
…结果是一样的! 驱动 Task 从它对 send 的调用中接收 future, 当 future 被解析后它将新的结果返回给协程。
到处使用 yield from 有什么好处呢? 为什么使用 yield 等待 future 和使用 yield from 委托给子协程更好? 它更好是因为,一个方法可以不影响 caller 而自由地改变它的实现: 它可能是一个普通的方法,返回将会 解析 为一个值的 future , 或者它可能是一个包含了 yield from 语句的协程,并且 返回 了一个值。 无论是哪种情况,caller 仅需要从方法中 yeild from 以此来等待结果。
至此,我们到了 asyncio 中协程的尾部。 我们仔细了解了生成器的工作机制,大概勾勒了 future 和 task 的实现。 当然了,实际的 asyncio 要比我们勾勒的版本要复杂得多。真正的框架解决了 另附纸 I/O, 公平安排,异常捕获和一些其他丰富的特性。
对于 asyncio 的用户而言, 使用协程来写程序要比上面看到的要简单得多。 在上面的代码中,我们从第一个原则起实现了一个协程,里面包括了 callback, task 和 future. 你甚至看到了非阻塞式的 socket 和对于 select 的调用。 但是当使用 asyncio 来真正构建一个应用时, 上面的代码并不会出现。如我们所望,你可以像下面一样简洁地获取一个 URL:
@asyncio.coroutine
def fetch(self, url):
response = yield from self.session.get(url)
body = yield from response.read()
对于协程的阐述到此告一段落,下面回到一开始的任务: 使用 asyncio 写一个异步爬虫.
This future has many deficiencies. For example, once this future is resolved, a coroutine that yields it should resume immediately instead of pausing, but with our code it does not. See asyncio’s Future class for a complete implementation.↩ ↩
In fact, this is exactly how “yield from” works in CPython. A function increments its instruction pointer before executing each statement. But after the outer generator executes “yield from”, it subtracts 1 from its instruction pointer to keep itself pinned at the “yield from” statement. Then it yields to its caller. The cycle repeats until the inner generator throws StopIteration, at which point the outer generator finally allows itself to advance to the next instruction.↩ ↩
⤧ Next post 用表情符号解释比特币 (1) ⤧ Previous post 用异步协程写一个爬虫 (1)